Hadoop is everywhere, especially this past week. Partnerships, products, clouds — it was nearly impossible to keep up with the news coming out of New York. It’s further evidence that Hadoop is cementing its role as the enterprise’s big data operating system. And, while I’ve been historically outspoken on Hadoop’s features and delivery platforms, what excites me most about the ecosystem is actually the release of Hadoop 2.2.0 (aka Hadoop 2).
This might be surprising, because Hadoop 2 is not a blow-your-socks-off release. It is not packed with revolutionary new features from a user perspective. Instead, its greatest innovation is a glorious refactoring of some internal plumbing. But that plumbing grants the community of Hadoop developers the pathways they need to address some of Hadoops greatest shortcomings in comparison to both the commercial and the internal Google tools that Hadoop was derived from.
Most notably, version 2.2.0 is the seed that may well revolutionize Hadoop’s offerings for greater scale, more processing models than MapReduce and truly multitenant operations.
Spinning a better Sweater via YARN
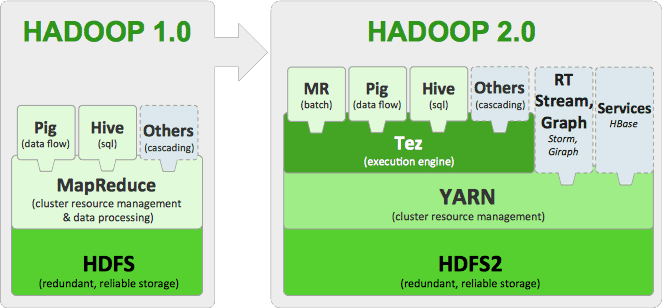
Hadoop 2 is all about YARN (a clean factorization of cluster resource management from the data processing models) going mainstream. While it may be a bit raw compared to commercial alternatives, YARN’s job is to manage the load across all the nodes in a Hadoop cluster, schedule application execution on the cluster, and move the processing close to the data. The main focus of YARN is on distributed resource management — something we’ve worked on intimately in scientific grid computing and in our own distributed database service at Cloudant.
YARN lays the foundation for people to build more things into Hadoop. It splits out distributed processing capabilities from the algorithms being applied to process data. MapReduce 2 is still the default, but new processing models are already available (see below), and developers of those algorithms won’t have to worry about things like job scheduling, fault tolerance and check-pointing strategies. Moreover, the need to “speak MapReduce” caused significant impedance mismatches as the community worked to layer additional functionality and interfaces on top of Hadoop. Those days are over.
Federation
The other major addition in Hadoop 2 is federation within the Hadoop distributed file system (HDFS). While the impact may not be immediately obvious, federation is a crucial step to allow HDFS to scale and to enable multitenant operations, both critical requirements in enterprise class data warehousing.
Federation in 2.2.0 works by allowing cluster nodes to participate in file storage for multiple namespaces (think directories, blocks, files, et cetera), and for namespaces to scale horizontally with additional “namenodes.” Not only does this allow Hadoop to scale beyond 4,000 nodes, but also it is the primitive to allow enterprises to share storage and processing nodes among a community of trusted users by “chopping up” the farm and sharing the resources at both at rest and at run time.
Impact
It’s not crazy to predict that federation and YARN are going to revolutionize Hadoop as we know it. In fact, it’s already happening. YARN has been available in technical preview for just over a year, but the community has already adapted to build SQL, stream processing, graph processing and more directly into Hadoop (via YARN ) instead of on top of Hadoop (via MapReduce). Perhaps one of the most significant early victories was Cloudera’s Impala, a Google Dremel clone for interactive queries over petabytes of data using SQL.
Combined with fledgling primitives for multi-tenant operations, Hadoop is rapidly solidifying as the platform for enterprise data warehousing. Perhaps most excitingly, the myriad new tools and interfaces enable the full analytics development cycle, from data integration (HDFS + “schema on read”) through ad hoc exploration (Hive, Impala, et cetera) to production workflows (incremental and/or batch).
Hadoop v2 sends a clear statement from the open source community that it recognizes the limitations of batch processing and MapReduce, and that the community is working to give developers new ways to do more. Much in the way that Google moved beyond MapReduce, the Hadoop ecosystem is following in its footsteps.
There are still plenty of rough edges, however. With the ability to build directly into Hadoop, developers lose the approachability of simplified processing interfaces like MapReduce. That means opportunity for high-level services (e.g., Continuuity’s Reactor) or analytic user interfaces (e.g., Tableau and Excel) to put the power of Hadoop into the hands of the masses via user interfaces. Federated HDFS is a big step, but there are still questions to answer about application containerization, security, heterogeneous runtimes, et cetera, for true multitenant operations.
Finally, with the rapid pace of cross-product integration with Hadoop, it will be very interesting to watch whether Hadoop, a truly open source community, can outpace its roots and innovate faster than its inspiration — Google.
Mike Miller is co-founder and chief scientist of NoSQL database startup Cloudant.
via Gigaom http://feedproxy.google.com/~r/OmMalik/~3/IXqrtHyI3g4/












{kind=link}
0 comments:
Post a Comment